一致性会在不同场景下被提及,其代表的含义也经常不同,对应的英文术语也是不一样的:Consistency,Consensus,Coherence等等。因此一致性是一个跨领域综合学科的名词,大概是最容易造成困惑的概念之一。
1、关于一致性
我们经常能听到“一致性”,“一致性”也是面试的常客。然而,不幸的是“一致性”在不同的领域和场景中,虽然都是叫一致性,但是含义也是不同的,一致性被极大的滥用了。
ACID中的consistency、Raft或Paxos中的consensus、MESI cache 一致性协议中的conherence?亦或者是CAP Theory中的consistency?
不得不承认这些 consistency,coherence,consensus(实际应该是共识)『一致性』为每一个想要了解数据库体系结构以及分布式系统的开发者造成了巨大的困扰。
一直以来,在“分布式系统”和“数据库”两个学科中,一致性(Consistency)都是重要的概念,但他们表达的内容并不相同。
对于分布式系统而言,一致性是在探讨当系统内一份逻辑数据存在多个物理数据副本时,对其执行读写操作会产生什么样的结果,这也符合CAP理论对一致性的表述。
在数据库领域,“一致性”与实务密切相关,又进一步细化到ACID四个方面,其中I所代表的的隔离性(“Isolaction”),是“一致性”的核心内容,研究的就是如何协调实务之间的冲突。
Raft、Paxos分布式一致性算法准确来说应该是分布式共识算法,Consensus,理解为共识更合适。主要解决的问题也是分布式环境下,多个节点达成共识,不属于一致性领域。下文主要讨论分布式领域的『一致性』和事务『一致性』。
3、分布式『一致性』
正是由于分布式系统中多个实体或者多个备份的特点,才产生了一致性的概念。从字面意义上来说,『一致性』关注的是分布式系统中不同实体之间数据或者状态的一致程度;而从实际的角度来看,『一致性』其实反映了系统对 client 提供的服务所表现出的特征。因此,本文以及后文将从 client 的角度出发,来分析分布式系统中不同的一致性保证。
3.1、一致性模型
一般而言,分布式系统中的一致性按照从强到若可以分为四种:
- 线性一致性(Linearizability:Strong consistency or Atomic consistency)
- 顺序一致性(Sequential consistency)
- 因果一致性(Causal consistency)
- 最终一致性(Eventual consistency)
我们常常还听到弱一致性(weak consistency)、强一致性(strong consistency)和最终一致性(eventually consistency)的说法,实际上这种叫法并不是指具体的一致性模型,它只是一个归类的概念。
通常将Linearizability和Sequential归为强一致性,将Causal consistency归为弱一致性。
Eventual Consistency目前尚没有形式化的定义,主要集中在How Eventual 和 What Consistency两个方面。
3.2、线性一致性(Linearizability)
线性一致性又被称为强一致性或者原子一致性。Maurice P. Herlihy 与 Jeannette M. Wing 在 1987 年的论文[2]中形式化的给出了 Linearizability 的概念。原始论文中线性一致性是基于 single-object (e.g. queue, register) 以及 single-operation (e.g. read, write, enqueue, dequeue) 的模型来定义的。因此,如果我们要在任意的分布式系统中严谨地讨论 Linearizability,就需要将系统以某种方式归约到这个模型中。
Linearizability 实际上刻画了我们对于分布式系统的非常自然的期望:
- 每一个读操作都将返回『最近的写操作』(基于单一的实际时间)的值
- 对任何 client 的表现均一致
注意上面『基于单一的实际时间』这几个字,这表明读写的先后顺序是由一个统一的实际时间(例如某个钟)来决定的,而不由逻辑时间所决定。在此要求下,系统的表现就像按照某个实际的时间顺序来处理所有 client 的读写请求。这个描述看起来不是很好理解,我们通过例子来详细说明。假定 Inv(X)Inv(X) 表示 XX 操作的起始, Res(X)Res(X) 表示 XX 操作的结束,横轴表示统一的时间,如下示例图显示了进程 P1 和 P2 的操作时序图:
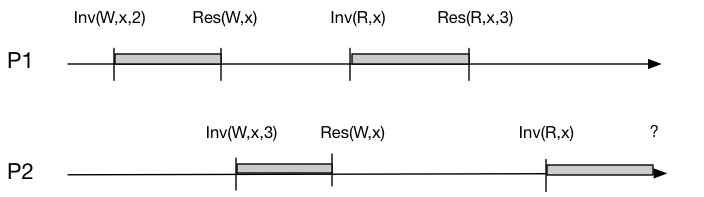
- 对于所有的 client 而言,其表现得如同采用了某种顺序来串行地执行所有进程的读写操作;
- 在这种顺序下,所有的读操作均能返回最近的写操作的值;
3.3、顺序一致性(Sequential consistency)
在 Herlihy & Wing 提出线性一致性之前,Lamport 早在 1979 年就提出了顺序一致性(Sequential consistency)的概念[3]:
A multiprocessor system is sequentially consistent if the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program.
值得注意的是,Lamport 上述的定义是基于 shared-memory multi-processor system 的。我们可以将这种系统理解成一个同步分布式模型,从而扩展该定义到分布式系统领域。
这个定义实际上对系统提出了两条访问共享对象时的约束:
- 从单个处理器(线程或者进程)的角度上看,其指令的执行顺序以编程中的顺序为准;
- 从所有处理器(线程或者进程)的角度上看,指令的执行保持一个单一的顺序;
约束 1 保证列单个进程中的执行按照程序顺序来执行,约束2保证了所有的内存操作都是原子。这里我们可以发现这里的约束和线性一致性相比,宽松了很多,这里只是要求按照编程顺序而不再是时间顺序了。为了更好的理解这两个的差异,我们同样用一组示例来解释:
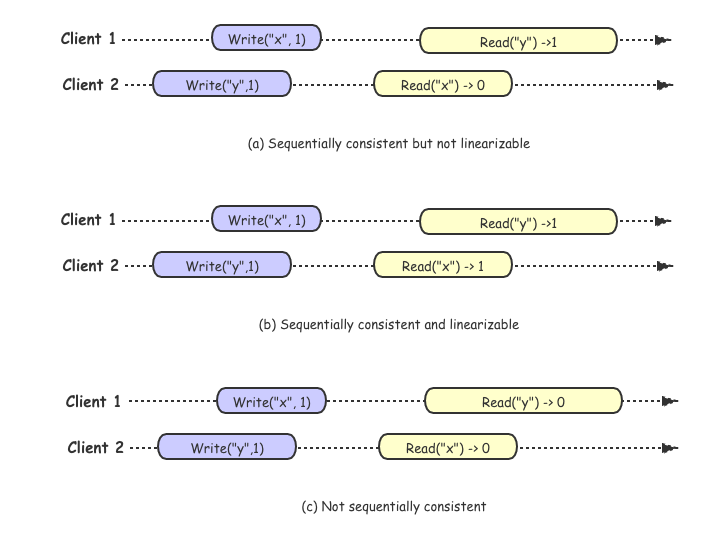
- (a)Sequentially consistent bug not linearizable
- Sequentially consistent:顺序一致性不要求绝对的时间顺序,只要单个处理器满足变成顺序,针对图(a),我们可以找到这样的执行顺序:
Write("y",1) →Read("x")->0→Write("x",1)→Read("y")->1满足顺序一致性 - not linearizable:线性一致性要求Write(“x”,1)先与Read(“x”)->0,read确没有读到最新的值
- Sequentially consistent:顺序一致性不要求绝对的时间顺序,只要单个处理器满足变成顺序,针对图(a),我们可以找到这样的执行顺序:
- (b)Sequentially consistent and linearizable
- 我们可以找到执行顺序:
Write("y",1) →Write("x",1)→Read("x")->0→Read("y")->1满足线性一致性要求,满足线性一致性,必然满足顺序一致性;
- 我们可以找到执行顺序:
- (c)not sequentially consistent
- 顺序一致性要求
Write("x",1)→Read("y")->0&&Write("y",1)→Read("x")->0,无法知道合理的顺序满足要求
- 顺序一致性要求
3.3、因果一致性(Causal consistency)
因果一致性的基础是偏序关系,也就是说,部分时间顺序可以比较的。至少一个节点内部的时间是可以排序的,依靠节点的本地时钟就行了;节点如果发生通讯,则参与通讯的两个事件也是可以排序的,接受方的事件一定晚于调用方的事件。
4、事务『一致性』
ACID一致性的概念是,对数据的一组特定约束必须始终成立。即不变量(invariants)。或者事务观察到的数据,总是要满足某些全局的一致性约束条件,如唯一约束,外键约束等。
原子性,隔离性和持久性是数据库的属性,而一致性(在ACID意义上)是应用程序的属性。应用可能依赖数据库的原子性和隔离属性来实现一致性,但这并不仅取决于数据库。因此,字母C不属于ACID1。
5、延伸:Linearizability VS Serializable
- Serializable 分支代表数据里的隔离性(Isolation),是一种并发安全保证。这些模型聚焦于解决由于并发冲突而导致的数据可见性和原子性问题。例如Serializable保证并发事务表现的像没有并发一样依次执行。这个分支下的模型假设数据只有一个副本。
- Linearizable 分支代表副本一致性,也是CAP中的C (Consisitency),是一种数据实时性保证。这些模型聚焦于解决数据多个副本间因复制滞后所产生的实时性和有序性问题。例如最强的Linearizable保证数据像只有一个副本一样实时。这个分支下的模型假设数据的读写事务是原子性的,即没有并发问题。
- 关于线性性(Linearizability) 跟可序列化(Serialization) 的关系。这两者看起来似乎相同,然而却是完全不同的两个概念。可序列化(Serialization) 的定义来自于数据库领域,是针对事务的概念,描述对一组事务的执行效果等同于某种串行的执行,没有 ordering 的概念;而 Linearizability 来自于并行计算领域,描述了针对某种数据结构的操作所表现出的顺序特征。详细内容可以看 这里;
- 关于使用 2PC 来保证线性一致性的说法。2PC 和 3PC 是分布式事务领域的概念,是用来实现分布式事务,而事务的存在主要是保证数据库本身的内部一致性。Linearizability 在前文强调过,是针对 single-object 以及 single-operation 的模型而定义。所以这种说法在描述上并不准确。关于如何实现 Linearizability,可以采用 Active Replication 或 Chain-replication 的系统模型。
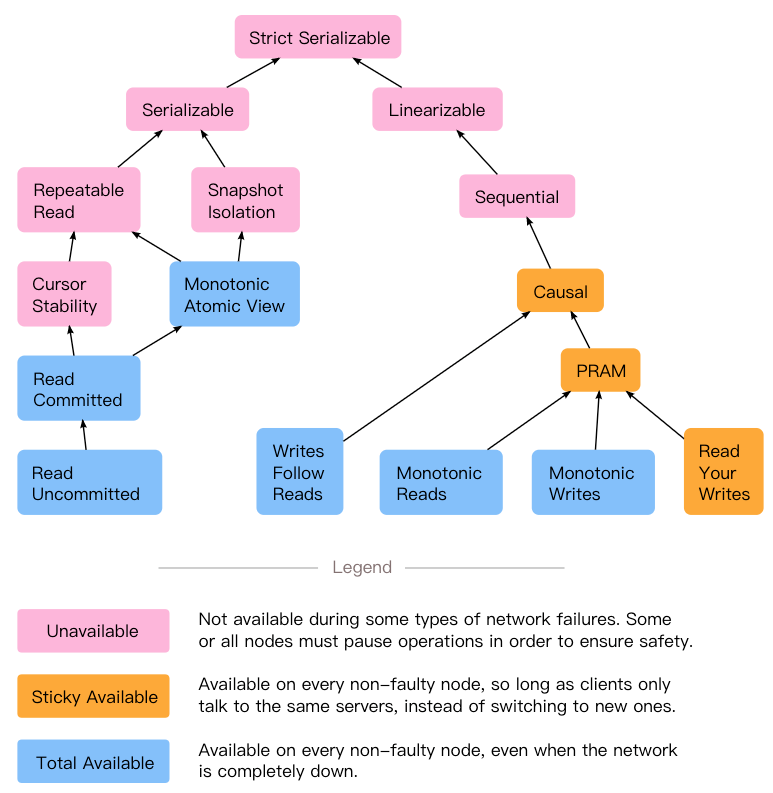
6、总结对比
- CAP中的C指的是分布式一致性范畴,具体指线性一致性,强调的是多个副本,单操作的数据一致性。ACID中的C是事务一致性范畴,强调单个副本,多操作的一致性,多操作跟A、I、D不同,原子性,隔离性和持久性是数据库的属性,而一致性(在ACID意义上)是应用程序的属性。而Paxos协议的一致性准确的来说应该叫共识,Consensus。
- 分布式中的一致性模型主要针对的是single-object、single-operation的范畴,但是数据库讨论的是multi-object、multi-operation的范畴,
参考文档
乔·海勒斯坦(Joe Hellerstein)指出,在论Härder与Reuter的论文中,“ACID中的C”是被“扔进去凑缩写单词的”【7】,而且那时候大家都不怎么在乎一致性。 ↩