在今天的互联网技术中心,日志技术用于方方面面。比如数据库、消息队列、分布式系统等等。只要涉及持久化、多副本就离不开日志技术。更好的理解日志技术,有助于我们更好的理解持久化和分布式系统;
1、关于Log
日志是totally-ordered,append-only的数据结构,我们经常用到,但可能我们还并没有意识到,因为他太简单了。关于Log,最容易想到的就是log4j、syslog这类文本日志,主要是为了方便人去阅读的调试信息。我们称之为应用日志。应用日志实际上是Log的一种退化,也不是本文今天讨论的重点。
日志技术是主要的宕机恢复技术之一,日志技术最早使用与数据库系统中,我们先从Mysql中的日志说起:
general log:记录所有的操作日志,会耗费数据库5-10%的性能,一般不打开。常用语sql审计和排错;Redo log:重做日志,用于InnoDB实现持久性,Redo log、Check point可实现宕机恢复;Undo log:回滚日志,用于实现InnoDB的原子性;Binglog:Mysql的逻辑日志,用户Mysql的主从复制;
从分类上来看,general log更偏向应用日志,Redo log、Undo log、Binlog属于数据日志,称为data log或者journal log。
而数据日志又可分为逻辑日志和物理日志:
- 逻辑日志(
physical logging):记录每一行的改变的内容,描述具体某一个Page的修改操作;Mysql InnoDB的redo log、undo log属于物理日志(准确来说应该属于physiological logging:物理日志和逻辑日志的混合); - 逻辑日志(
logical logging):记录的不是改变的行,而是引起行改变的SQL语句,相比于逻辑日志,又被成为high-level logging,不关心具体作用于哪一个page,得益于更高层次的抽象,一条逻辑日志,可以对应多条物理日志。Mysql binlog属于逻辑日志;
除物理日志和逻辑日志以外,还有一种日志被称为physiological logging,试图同时获得物理日志和逻辑日志的优势。
1.1、日志的抽象
日志是一种简单的的存储抽象,只能追加(append only)、不可变、按照时间完全有序(total-orcered)的记录序列:
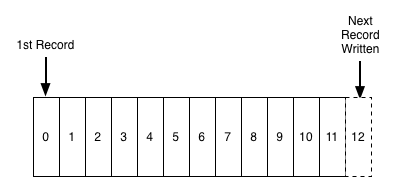
在日志的末尾添加记录,读取日志记录则从左到右。每一条记录都制定一个唯一的顺序日志记录编号。
日志的次序(ordering)定义时间』概念,因为位于左边的日志记录表示比右边的早。日志记录编号可以看作是这条日志记录的『时间戳』。把次序直接看成是时间的概念,刚开始觉得有点怪异,但是这样的做法有个便利的性质:解耦了时间和任意特定的物理时钟(physical clock)。引入分布式系统后,这回成为一个必不可少的性质。
1.2、日志技术:数据持久性保证
要保证数据的持久性,我们需要将数据落盘持久化。现在数据库基本都是使用WAL(Write Ahead Logging)预写日志来实现的。
在单机系统中,宕机恢复主要依赖WAL+Checkpoint技术,但是在分布式系统中,要保证数据的持久性,需要引入多副本技术,要实现多副本,就离不开日志复制技术(Log Replication)。
2、WAL(Write-Ahead Logging)
WAL是一种实现事务日志的标准方法。WAL的标准思想是先写日志,再写数据,数据文件的修改必须发生在这些修改已经记录日志文件之后。
如果每次发生数据变化,就将变更的数据页刷到磁盘,那么这个开销是非常大的。如果数据集中到几个热点数据页,那么性能会非常差。同时如果在从缓冲池将页数据刷到磁盘前发生了宕机,那么数据库就不能恢复了,为了避免发生数据丢失问题,当前事务数据系统普遍采用了Write Ahead Log策略,即当事务提交时,先写重做日志,再修改页。当由于宕机而导致数据丢失时,通过重做日志来完成数据恢复。这也是事务ACID中的D(Durability)的要求。
WAL机制可以从两个方面提高性能:
- 多个client写日志文件可以通过一次fsync来完成
- 日志文件是顺序写的,同步日志的开销远比同步数据页的开销要小
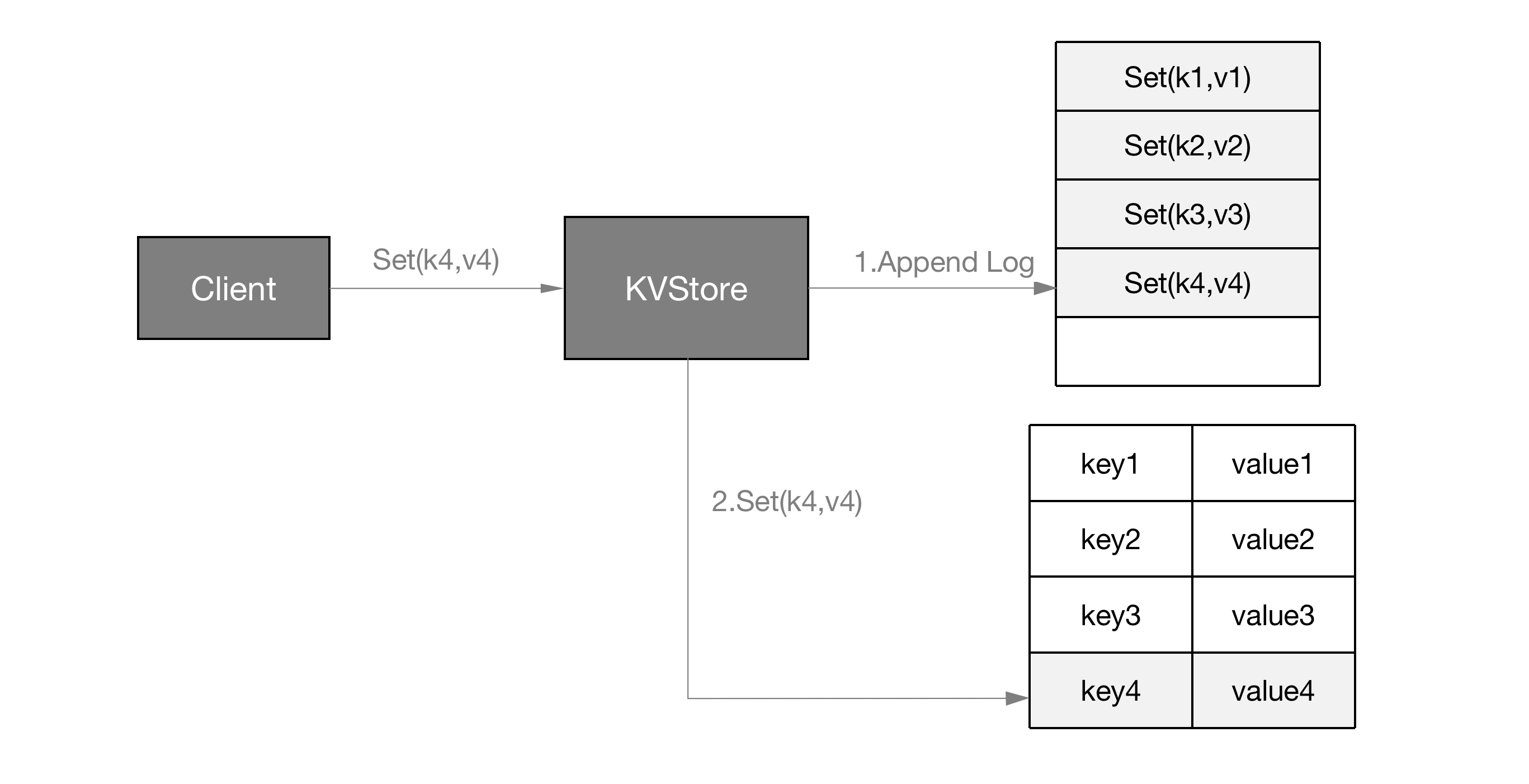
采用单个日志,可能变得很难管理:
- 清理老日志困难
- 重启时读取文件过大
为了解决这个问题,通常采用分段日志(Segmented Log)或者最低水位线(Low-Water Mark)来减少程序启动时读取文件大小以及清理老日志。
2.1、Segmented Log
单一的日志文件可能会增长到很大,并且程序启动时读取从而成为性能瓶颈。老的日志需要清理,对于一个大的文件清理操作很费劲。将一个日志切分为多个,日志在达到一定大小时,会切换到新文件继续写。
2.2、Low-Water Mark
WAL预写日志维护了对存储的每次更新,随着时间的不断增长,这个日志文件会变得无限大。Segmented Log分割日志可以让我们每次只处理一个小文件,但是如果不清理,会无休止增长以至于硬盘被沾满。
最低水位线标记哪一步日志可以被删除了,即在最低水位线之前的所有日志都可以清理掉。一般的实现方式是程序内有一个定时运行的线程,来清理水位线以下的日志文件。
2.3、Checkpoint技术
如果WAL日志可以无限增大,同时缓冲池也足够大,能够缓冲所有的变更数据,那么就不需要讲缓冲池的数据刷到磁盘。因为发生宕机的时候,完全可以通过WAL日志来恢复整个数据系统。但是这需要满足两个前提条件:
- 缓冲池足够大
- WAL日志足够大
当然,还需要考虑另外一个问题,宕机恢复时间问题。因此Checkpoint技术的目的是解决以下几个问题:
- 缩短数据库的恢复时间
- 缓冲池不够用的时候,触发fsync
- WAL日志不够用,触发fsync
LSN(Log Sequence Number)
LSN通常用来标记版本,单调递增且唯一,通常WAL也LSN,Checkpoint也有LSN。
2.4、幂等
WAL是顺序Append的,当网络或者其他问题触发重试时,WAL实现幂等的代价是很大的,可能会生成重复的日志,需要WAL刷盘的时候通来保证幂等;
2.5、工程投影:Twitter DistributedLog
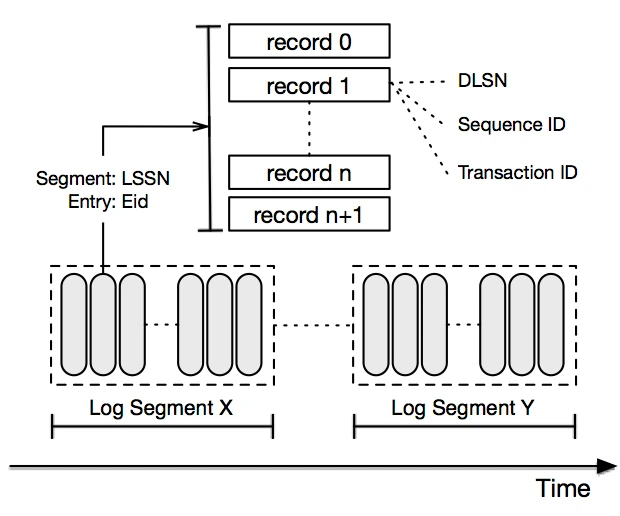
每条日志记录都是一个字节序列。日志记录会按照序列写入到日志流中,并且会分配一个名为 DLSN(分布式序列号,DistributedLog Sequence Number)的唯一序列号。除了 DLSN 以外,应用程序还可以在构建日志记录的时候设置自己的序列号,应用程序所定义的序列号称为 TransactionID(txid)。
[注]InnoDB的Redo Log的RingBuffer结构
3、Log Replication
WAL+checkpoint在单机系统下可以很好的应对故障恢复。但是在分布式系统中,我们需要通过多副本技术来应对单节点故障,多副本最常用的技术就是日志复制技术。
日志解决了两个问题:更改动作的排序和数据的分发,这两个问题在分布式系统中尤为重要。协商达成一致的更改动作顺序是分布式系统设计的核心问题一致。
分布式系统以日志为中的方案来自于一个简单的观察,我们称之为状态复制机原理(State Machine Replication Principle)
3.1、Log Replication State Machine
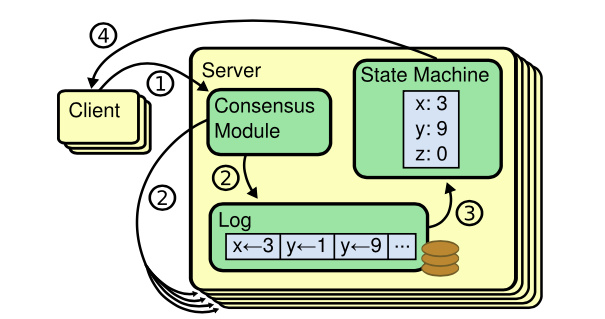
复制状态机的结构。一致性算法管理着来自客户端指令的复制日志。状态机从日志中处理相同顺序的相同指令,所以产生的结果也是相同的。
3.2:工程投影:Mysql的主从复制技术
待补充
4、日志与表的二象性
二象性(
duality)是个冷门词汇。我唯一在『光的波粒二象性(wave-particle duality)』一词中有接触,是指光(电磁波)有时会显示出波动性(这时粒子性较不显著),有时又会显示出粒子性(这时波动性较不显著),在不同条件下分别表现出波动或粒子的性质。 波动性/粒子性是人们对光的认识、理解或描述方式。类似的,数据表现出了表与事件的二象性,表与事件是数据在不同条件/场景下数据的性质,是对人们对数据的认识、理解或描述方式。
如果上面描述你觉得『二象』一词还是很难理解,你可以理解成『对偶』、『互通』、『对称』或『可逆』,即数据表 和 数据事件之间可以互相转化。
数据库、缓存、消息队列:
相同:存储一段时间的数据
不同:访问模式不同,有不同的性能特征和实现手段;
消息队列:日志数据流
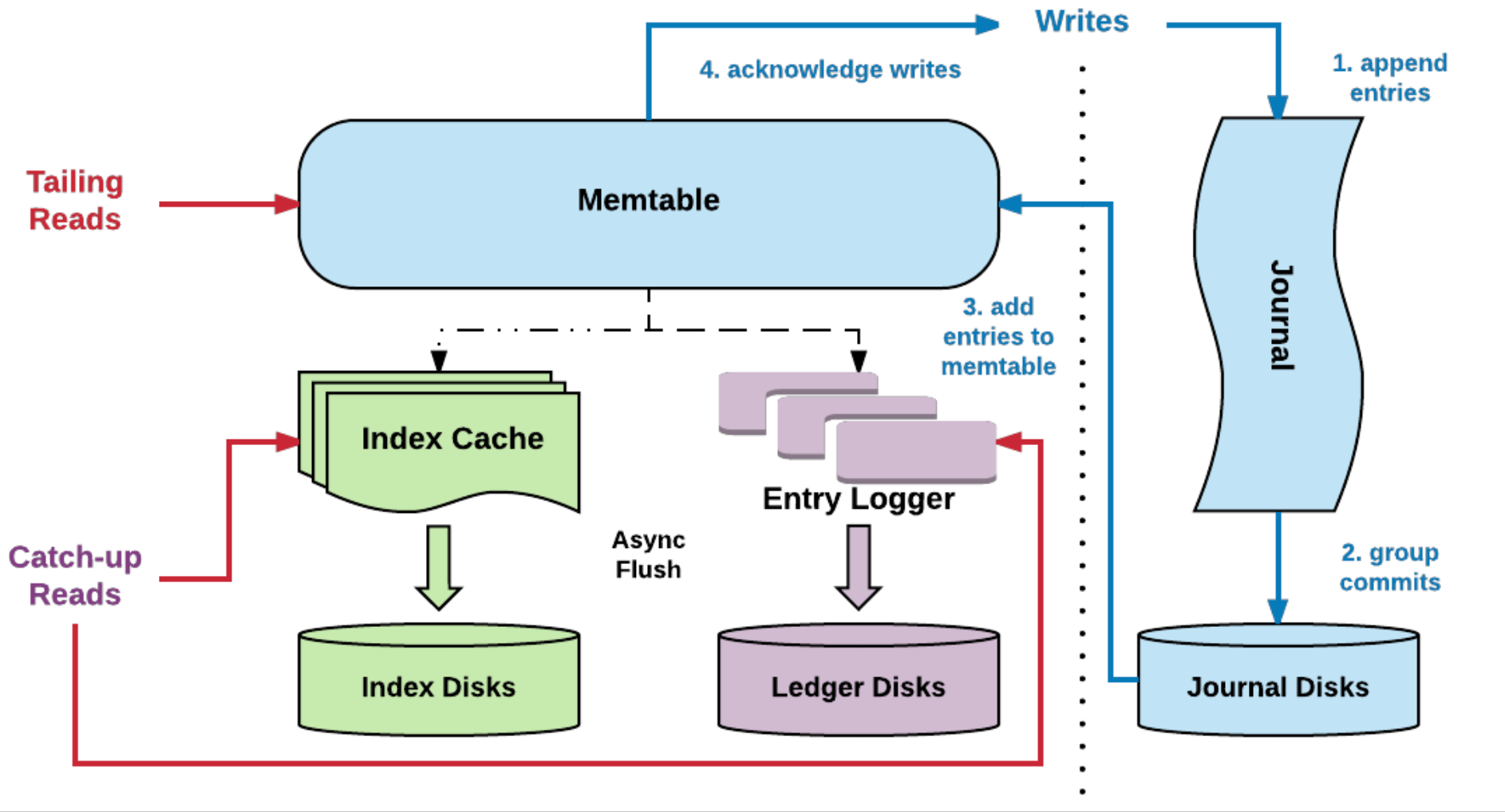
4.1、工程投影:Pulsar 消息和流一体的消息队列
参考文档
http://mysql.taobao.org/monthly/2017/03/02/
https://github.com/oldratlee/translations/blob/master/log-what-every-software-engineer-should-know-about-real-time-datas-unifying/part1-what-is-a-log.md
https://spongecaptain.cool/post/database/logicalandphicallog/
https://zhuanlan.zhihu.com/p/350131538
https://martinfowler.com/articles/patterns-of-distributed-systems/log-segmentation.html
https://bravenewgeek.com/building-a-distributed-log-from-scratch-part-1-storage-mechanics/
https://www.infoq.cn/article/2016/05/twitter-github-distributedlog