Approaches to Consensus
Part1. Consensus
分布式中唯一问题:对某个事达成一致。e.g.
- 分布式锁:分布式系统下,多个节点确定一个唯一的值
- leader election:分布式系统下多个节点确定一个唯一的master
1.1. Model of Distribute System
- Network
- reliable, fair-loss, or arbitrary
- Node
- crash-stop, crash-recovery, or Byzantine
- Timing
- synchronous, partially synchronous, or asynchronous
1.2. Consensus system models
Paxos,Raft,ect. Assume a partially synchronous, crash-recovery system model
Why not asynchronous
FLP Result:FLP 证明了在异步网络下,没有任何算法能保证 进程/节点 达成一致
- liveness
- safety
1.3. Approaches to Consensus
- Symmetric, leader-less:(basic paxos)
- All servers have equal roles
- Clients can contact any server
- Asymmetric,leader-based:(multi-paxos,raft)
- At any given time,one server is charge, others accept its decisions
- Clients communicate with the leader
Part2. Paxos
这个世界上只有一种一致性算法,那就是Paxos …–Google Chubby的作者Mike Burrows
Implementing Replicated Logs with Paxos
paxos 存在问题:
- 难以理解
- 不具备良好的工程实践能力, multi-paxos 缺乏实现细节
Chubby 实现了类似 paxos 的算法, 但是不公开
Part3. Raft:Understanding the Raft consensus algorithm
3.1. 介绍
3.1.1. Raft’s Design Goals
Paxos is too complex and incomplete for real implementations
3.1.2. 为了可理解性设计
将问题分解成几个相对独立的,可被解决的、可解释的和可理解的子问题。Raft 算法被分成
- 领导人选举
- 日志复制
- 安全性
- 成员变更
减少状态的数量来简化需要考虑的状态空间,使得系统更加连贯并且在可能的时候消除不确定性:
- 所有的日志是不允许有空洞的,并且 Raft 限制了日志之间变成不一致状态的可能。
- 使用随机化来简化 Raft 中领导人选举算法
3.1.3. Replication Sate Machine
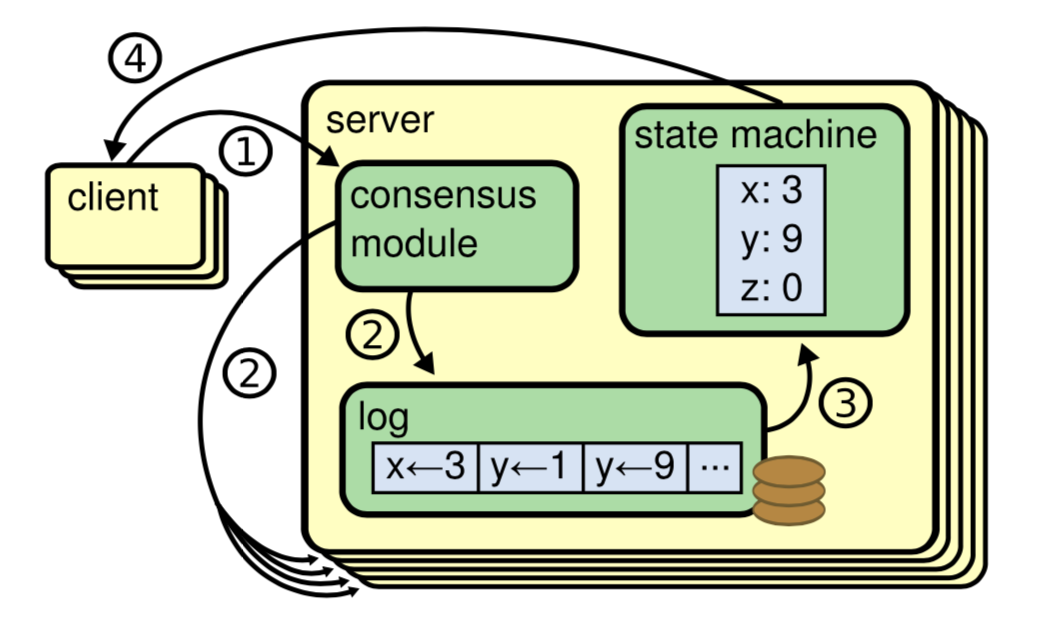
图 1 :复制状态机的结构。一致性算法管理着来自客户端指令的复制日志。状态机从日志中处理相同顺序的相同指令,所以产生的结果也是相同的。
3.1.4. 复制状态机的常见用例
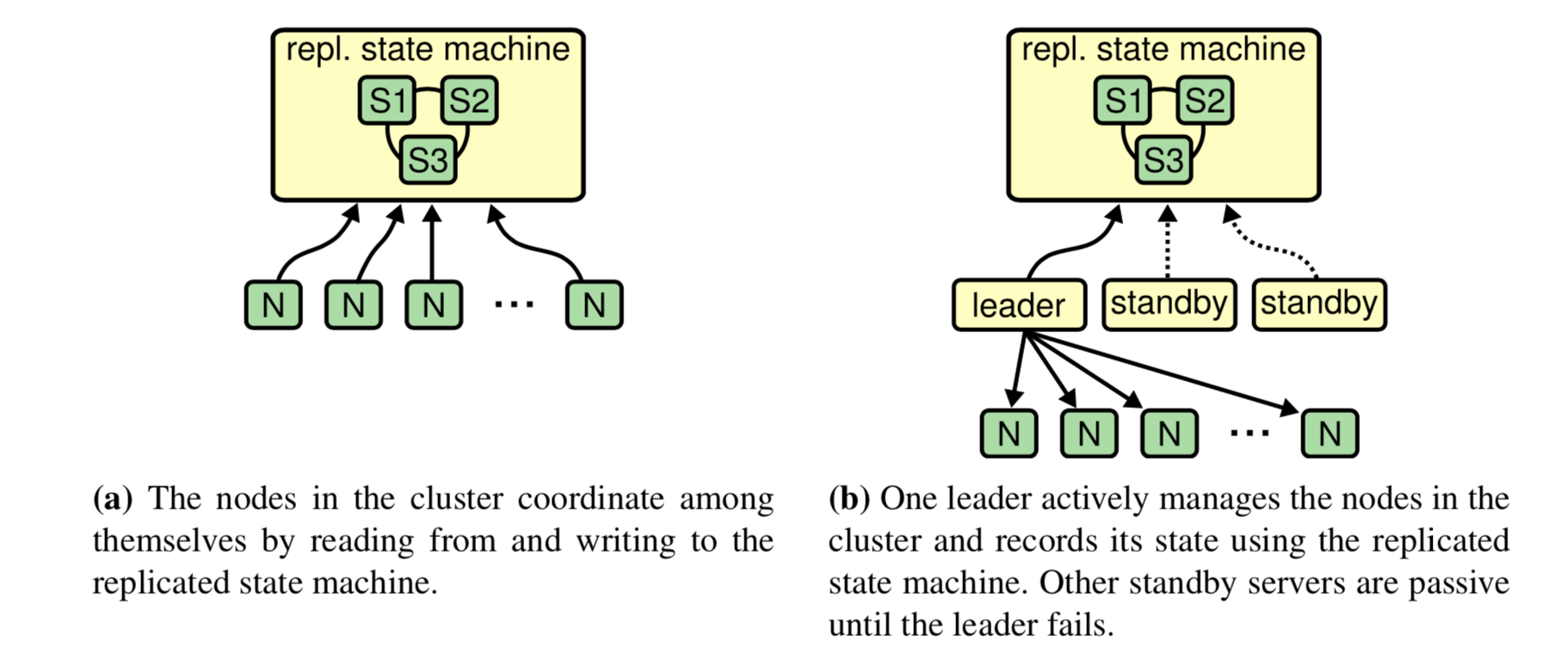
使用单个复制状态机的常见模式。
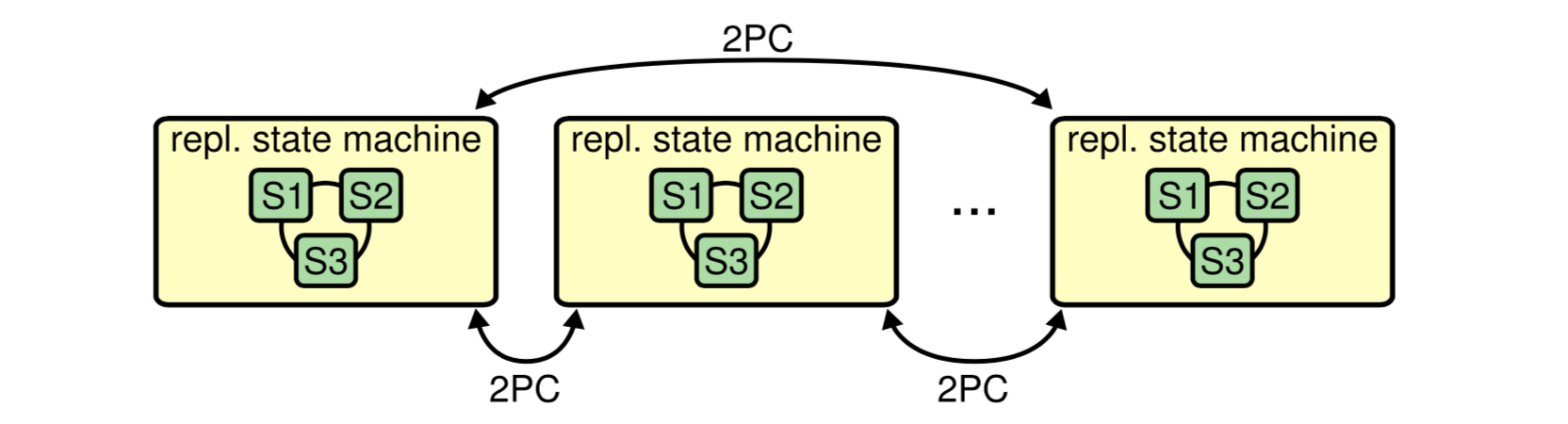
使用共识的大型分区存储系统。为了扩展,数据在许多复制状态机之间进行了分区。跨越分区的操作使用两阶段提交协议。
3.2. Raft算法基础
Raft首先在共识组中选出一个leader,然后由leader全权处理LOG的复制;leader首先从client处得到logentry,然后将该logentry请求复制转发到其他server中;在该logentry标记commited后,leader再通知其他server进行apply。这样由leader来统一处理,简化了日志的复制管理。由此,Raft算法可分为以下几个部分:
- Leader Election:当leader失效后,需要选举处一个新的leader。
- Log Replication:leader收到新log entry时,需要及时复制给其他server,并确保其他log与自己本地log达成一致。
- Safety:当某个server将某个log index处的log进行了apply后,那么在整个集群内,该log index处都应该apply同一条log。
- membership change:增加或删除共识组内的节点。
3.2.1. Raft概述:(浓缩总结)

3.2.2. Raft特性
Raft确保共识组运行中,始终满足以下五个特性:

- Election Safety:每个term中最多只有一个leader;见Leader选举章节
- Leader Append-Only:Leader对于自己的日志只会追加,不修改和删除;见Log复制章节
- Log Matching:如果两个日志包含一个logindex和term都相同的entry,那么该Entry之前的日志都相同;见Log复制章节
- Leader Completeness:如果一个log entry在某个term中已经提交了,那么之后的term换了leader,该commited的entry仍然在日志中。见Safety章节。
- State Machine Satety:如果状态机已经应用了某条日志,那么在该logindex处,不能apply其他entry。见Safety章节。
3.2.3. Server States
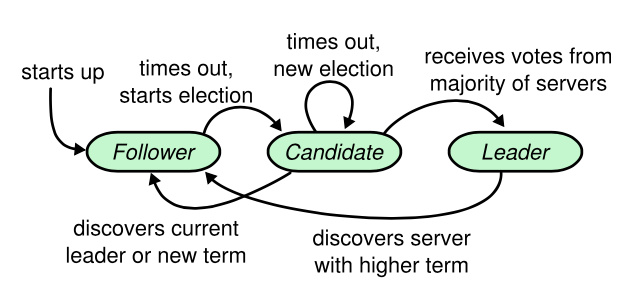
图 4:服务器状态。跟随者只响应来自其他服务器的请求。如果跟随者接收不到消息,那么他就会变成候选人并发起一次选举。获得集群中大多数选票的候选人将成为领导人。在一个任期内,领导人一直都会是领导人,直到自己宕机了。
3.2.4 .Terms
Term is logic time
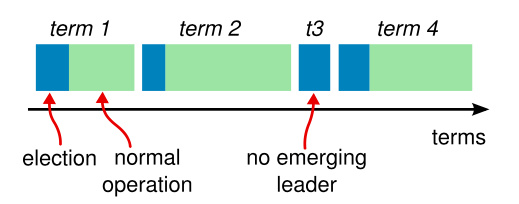
Time divided into terms:
- Election
- Normal operation under a singel leader
- Some terms have no leader(failed election)
- At most 1 leader per term
- Each server maintains current term value
3.2.5..Heartbeats and Timeouts
广播时间(broadcastTime) « 选举超时时间(electionTimeout) « 平均故障间隔时间(MTBF)
- Servers start up as follwers
- Follwers expects to receive RPCs from leader or candidates
- Leaders must send heartbeats to maintain authority
- If electionTimeout elapses with no RPCs:
- Follower assumes leader has crashed
- Follower starts new election
- Timeouts typically 100-500ms
3.3.Safety:
Safety:在故障发生时,共识系统不能产生错误的结果。
3.3.1.allow at most one winer per term
Each server gives out only one vote per term(persist on disk)
Two different candidates can’t accumulate majorities in same term
3.3.2.Leader completeness
选举限制:
Raft 使用了一种更加简单的方法,它可以保证所有之前的任期号中已经提交的日志条目在选举的时候都会出现在新的领导人中,不需要传送这些日志条目给领导人。这意味着日志条目的传送是单向的,只从领导人传给跟随者,并且领导人从不会覆盖自身本地日志中已经存在的条目
请求投票 RPC 实现了这样的限制:RPC 中包含了候选人的日志信息,然后投票人会拒绝掉那些日志没有自己新的投票请求。
Raft 通过比较两份日志中最后一条日志条目的索引值和任期号定义谁的日志比较新。如果两份日志最后的条目的任期号不同,那么任期号大的日志更加新。如果两份日志最后的条目任期号相同,那么日志比较长的那个就更加新。
3.7.3. commit entries from a previous term
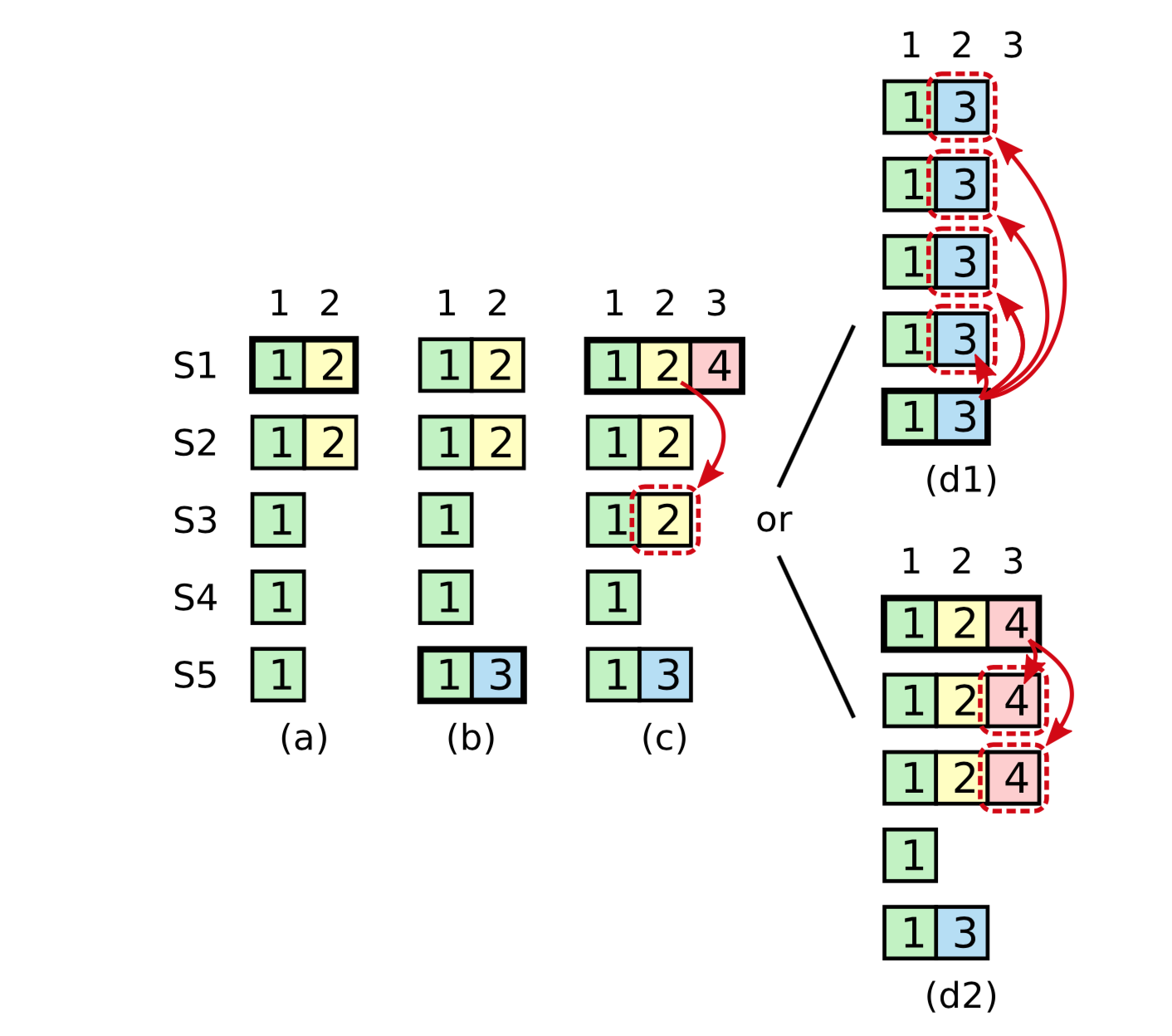
图 3.7:如图的时间序列展示了为什么领导者无法决定对老任期号的日志条目进行提交。在 (a) 中,S1 是领导者,部分的复制了索引位置 2 的日志条目。在 (b) 中,S1 崩溃了,然后 S5 在任期 3 里通过 S3、S4 和自己的选票赢得选举,然后从客户端接收了一条不一样的日志条目放在了索引 2 处。然后到 (c),S5 又崩溃了;S1 重新启动,选举成功,开始复制日志。在这时,来自任期 2 的那条日志已经被复制到了集群中的大多数机器上,但是还没有被提交。如果 S1 在 (d) 中又崩溃了,S5 可以重新被选举成功(通过来自 S2,S3 和 S4 的选票),然后覆盖了他们在索引 2 处的日志。反之,如果在崩溃之前,S1 把自己主导的新任期里产生的日志条目复制到了大多数机器上,就如 (e) 中那样,那么在后面任期里面这些新的日志条目就会被提交(因为 S5 就不可能选举成功)。 这样在同一时刻就同时保证了,之前的所有老的日志条目就会被提交。
- leader不能commit entries from a previous term,在(c)S1 commited preTerm的2是不被允许的。
- raft 的新的leader节点可以提交自己任期的日志条目,通过log matching的特性,如果当前的日志条目提交,前任期的日志间接的被提交。
另外,Raft对于旧的日志条目会发送旧的任期号,这使得日志更容易被理解和识别;
3.4.Liveness
系统能持续产生提交,也就是不会永远处于一个中间状态无法继续
3.4.1.Raft use randomized election timeout
- Choose election timeouts randomly in [T,2T]
- One server usually times out and wins election before others wake up
- Work well if T»broadcast time
3.4.2.preVote+checkQuorums
PreVote:集群中有一个节点能发消息,但是无法收消息,他会一直心跳超时,然后发起新的选举,导致leader下台
https://www.zhihu.com/question/483967518/answer/2097076504
3.5. reference
Raft:Slides from Diego Ongaro and John Ousterhout
Part4. Multi-Paxos VS Raft
Raft相比于Paxos更简单
- 共识问题简化成三个独立的问题: leader election、log replication、safety[logIndex->log唯一且不可变]
- 不允许类似paxos的乱序提交
- 使用 Randomization 算法简化leader election问题.
- 使用term概念代替原子钟的概念
4.1. Multi-Paxos允许日志出现空洞,Raft不允许
paxos是允许并发的,Raft不允许并发,Raft的leader的append必须是连续的。
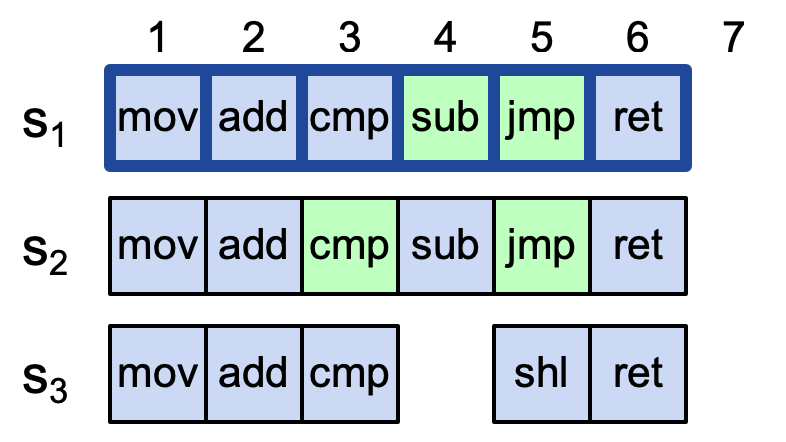
4.2. Raft选主有限制,要求Leader Completeness
选主是有限制的, 必须有最新, 最全的日志节点才可以当选. 而multi-paxos 是随意的 所以raft 可以看成是简化版本的multi paxos(这里multi-paxos 因为允许并发的写log, 因此不存在一个最新, 最全的日志节点, 因此只能这么做. 这样带来的麻烦就是选主以后, 需要将主里面没有的log 给补全, 并执行commit 过程)